2020 7 29
身份证号识别
1.数据预处理
通常输入分类器(神经网络)的图片的“变化”越少,分类效果越好,即分类器对输入图片有一定要求, 如尺寸、身份证号在图中位置等,因此需要对本程序读入数据进行预处理。数据预处理可以概括为 :边缘检测、ROI区域处理。下文将分别对这两部分进行详细介绍。
1.1边缘检测
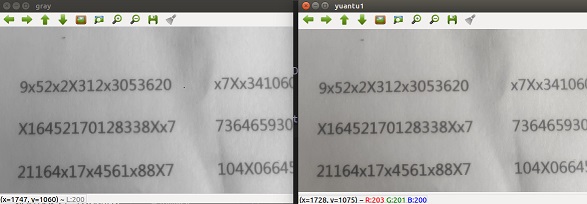
先将原图备份,方式数据丢失。为减少数据预处理的步骤的运算量,先将原图转化为灰度图, 对于“白底黑字”的身份证号而言,灰度图片与彩色图片并无明显差别,如下图。
同时为减少噪声影响,如身份证的底纹、相机镜头上的污点等。因此需要对输入图片进行“滤波”, 本文使用运算量相对较小的高斯滤波算法,给图片“降噪”,该算法并不能完全消除噪声影响, 同时对于较为明亮的拍摄环境,“噪声”较少,可以省略该步骤,以提升运算速率,如下图。 该算法中使用3*3的核进行高斯滤波,建议使用3*3或5*5的核,核过大将增加运算量, 同时使得图片的边缘模糊,不利于后续步骤。

在“白底黑字”的图片中,利用像素值求各处的“梯度”,在“黑白交界”处往往存在较大梯度,将梯度较大的区域筛选出, 便得到“黑白界面”,即文字边缘,根据边缘特征确定文字位置。
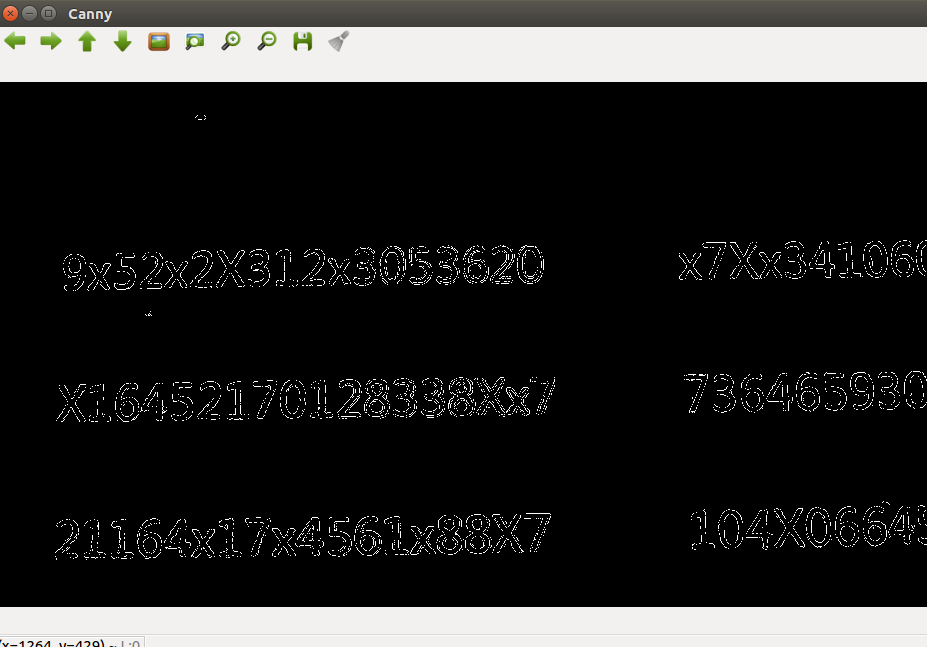
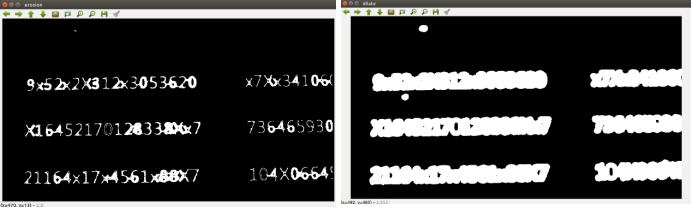
本文使用“Canny边缘检测算法”对输入图片进行边缘检测,以找出图片中身份证号所在区域,方便分类器进行分类。 利用Canny算法,进行边缘检测,不可避免的出现同一个文字的边缘“不连续”,不同文字边缘“ 粘连”的情况,如上图。需要使用“膨胀”操作,连接不连续边缘;使用“腐蚀”操作,分离“ 粘连”字符。考虑到传统“膨胀”操作,运算量较大,因此本文使用如下方法代替“膨胀”操作: ①使用较宽的白线条绘制边缘检测结果②重新查找边缘。 使用如下方法代替“腐蚀”操作:①使用较宽的黑线条绘制边缘检测结果②重新查找边缘。如下图(左为腐蚀,右为膨胀)
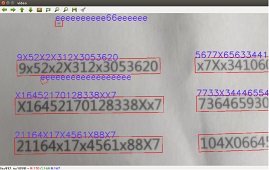
通常一个“边缘”包含十至数十个点,包含数据过多,难以筛选出“数字边缘”或“身份证号边缘”。因此使用最小包围矩形, 将每一个边缘进行“概括”为旋转矩形的四个特征值,可以根据:旋转矩形的面积,长宽比等特征 进行筛选。如需进行字符分割可以筛选出“长宽比接近1”、“面积大于50pixel^2(<50pixel^2 通常为噪声)”的矩形区域作为单个字符,再对每一个字符进行识别;如直接对身份证号整体进行 识别可以直接筛选出“长宽比大于阈值”的矩形作为ROI区域。
考虑到识别单个字符这一步骤需要重复18次,同时需要对识别结果进行排序,将大大增加计算量,因此本文使用 “对身份证号整体进行识别”的方案。为保证身份证号中18个字符作为一个整体,本文使用 “膨胀”操作使18个字符相互“粘连”,再计算旋转矩形,但在此过程中部分噪点也被“膨胀”。 噪点被膨胀后长宽比接近于1,因此可以根据旋转矩形的长宽比,筛选出“身份证号”,根据实际 测量,身份证号的长宽比为[9,11];在图像中,由于拍摄角度引起的畸变,该范围将扩大。 经过不断尝试,最终将长宽比的阈值,定为7,即旋转矩形的长宽比大于7,即可确定该区域为 身份证号所在。如果没有这一阈值, 就会像下图一样
1.2 ROI区域处理
在边缘检测过程中对图像进行“膨胀”操作,使得其中字符难以辨认。因此本文利用边缘检测所得 到的矩形的长宽、角度、位置,在原图中截取ROI区域。由于身份证每次摆放都会出现偏差, 造成ROI区域中文字倾斜,如图2-6,或是拍摄时相机角度不同,因透视现象产生的畸变等偏差 ,都会对分类器的效果产生影响,因此需要对所得ROI进行处理。
本文使用旋转矩形表示ROI,旋转矩形的角度,在一定程度上反应了文字旋转的程度, 因此对该旋转矩形进行校正,可以大大减小“文字倾斜”的现象。根据旋转矩形的角度计算旋 转矩阵,利用旋转矩阵对旋转矩形的各个像素点进行坐标变换。经过上述操作后,图片中的数 字无明显旋转,如下图:
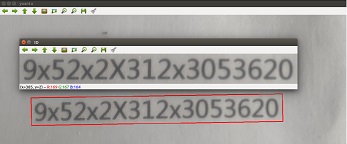
通过resize函数直接将图片修改为制定尺寸,既满足了分类器的输入要求,同时减小了透视现象造成的畸变。 由于拍摄环境亮度不同,造成的误差,也将影响分类器的分类结果,因此将图片减去平均值,后再输入分类器。
2.分类器设计
本文使用神经网络作为分类器,涉及神经网络的结构、数据集制作、训练、调用。
2.1神经网络结构
本文神经网络共10层(含输入输出层)。其中5层卷积层,三层池化层。具体结构如下
名称
核
输入
输出
image
40*448*3
conv1
5*5*3*64
40*448*3
40*448*64
pool1
40*448*64
20*224*64
conv2
3*3*64*128
20*224*64
20*224*128
pool2
20*224*128
10*112*128
conv3
3*3*128*64
10*112*128
10*112*64
pool3
10*112*64
5*56*64
conv4
3*3*64*32
5*56*64
3*54*32
conv4
3*3*32*12
3*54*32
1*18*12
result
1*18*12
18*12
输入图片大约为40*448时,在人眼看来较为清晰,无畸变;由于最终需要输出12*18的张量, 故从40*448逐渐过渡到12*18,个人认为张量尺寸的突变不利于网络的学习和使用.
对具体各层作用进行如下猜测:
从输入图片到conv4中的神经网络,用于突出图片特征,其中卷积层可以突出图片中边缘、角点等特征,
池化层可以筛除不明显特征;并实现字符分割,将单个字符的特征“归纳”到3*3*32的张量中。conv5从这些特征中计算出该字符。
conv5层根据之前被突出的特征,计算出该字符,输出1*18*12的张量conv5,
表示先关概率。例如conv5[0,0,0]表示第一个数为0的概率;conv5[0,4,6]表示第5个数为6的概率;
conv5[0,7,11]表示第8个数为“不可识别”的概率。
2.2数据集制作
由于没有现存的身份证号的相关数据集,因此本文需要自己制作数据集。通过随机数生成200组身份证号数据,并进行打印, 拍摄打印结果,得到了较为接近实际应用中可能得到的图片数据。
2.2.1图片数据
利用该程序的数据预处理部分,得到可以作为分类器输入的图片数据。
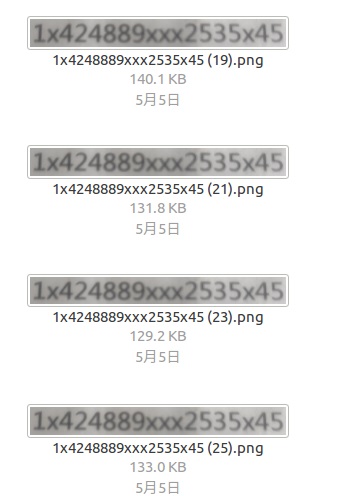
通过修改图片名称,为图片打标。命名规范为:身份证号+编号。
在读取数据时仅读取前18个字符,即可读入身份证号;编号的加入可以防止同一个身份证号被拍摄多次,如下图
身份证号有18个字符组成,本文认为每一字符有12中可能(1-9,x,“不可识别”),故共有18^12中组合
(不考虑,身份证号校验及其他规范)。理想条件下,应该让神经网络遍历每一种组合,才能达到最佳效果,
但通过修改图片名称的打标方式,不可能处理如此多的组合,因此本文采用打标数据+“组合数据”的方式制作训练集。
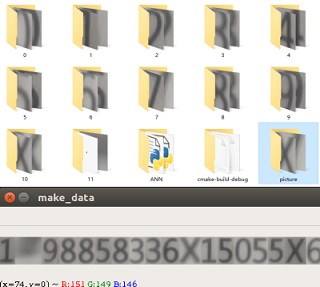
通过寻找ROI,再对ROI进行字符分割(上文中膨胀操作改为腐蚀, 同时修改阈值),便得到单个字符的多份数据(单字符数据集),
再使用时随机生成一组身份证号,根据身份证号在单字符数据集中找出相应字符,进行组合拼接,
得到相应的身份证号图片及标签,以此制作“组合数据”,如下图
2.2.3训练及保存
本文在电脑GPU上进行训练,使用CUDA10+GeforceRTX2060进行,共计训练2小时, 并保存相关训练结果,便于该网络在其他平台上进行调用。具体训练方法及参数如下。
使用交叉熵作为损失函数(loss),计算标签数据与神经网络输出数据的loss值。利用Adam优化器对神经网络进行优化, 学习率为0.001。batch size为8,共训练10万次,在训练1万次左右,loss值基本稳定。
当loss值较小时则将神经网络模型保存为.pb文件,方便OpenCV调用。保存为.pb模型后,使用optimize_for_inference.py对网络模型进行简化, 会自动删除模型中输入层与输出层之间所有不需要的节点,简化神经网络。
通过读取简化后的.pb文件并按照网络层名称,生成pbtxt文件,描述网络结构,有利于OpenCV调用。
2.2.4调用
使用OpenCV中dnn模块中的readFromTensorflow函数,读取pb和pbtxt文件,实现神经网络的复现。
但由于本文使用leaky_relu作为激活函数,可以防止负数部分数据丢失,但opencv3中并不能复现leaky_relu函数。 因此本文借助opencv::dnn中的相关接口,自定义并调用了leaky_relu函数。(具体请参考我的源代码)
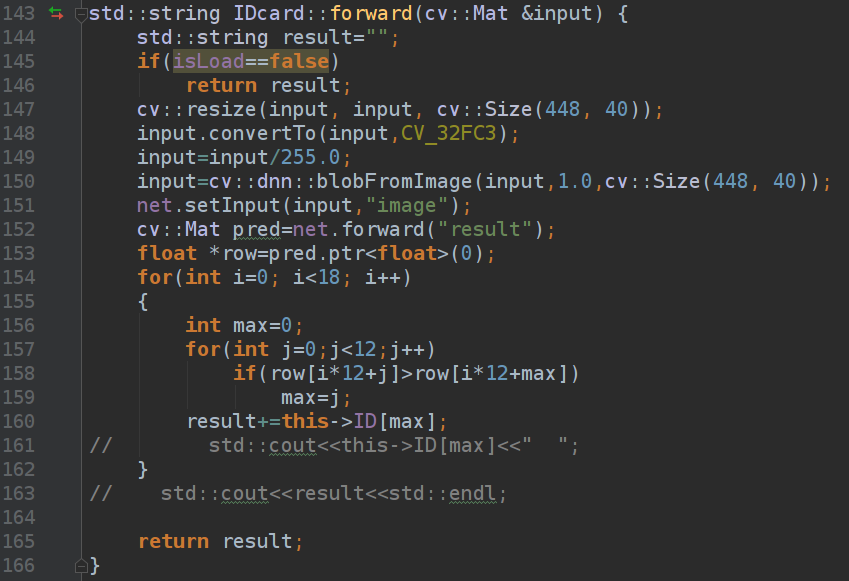
在opencv中完成对神经网路输出的解读:
3 软件测试
测试发现:
①对于明亮、清晰且拍摄完整的图片数据,本程序可以准确识别。
②对于存在阴影,或其他干扰时,程序无法准确找到ROI区域,导致该程序无法准确识别身份证号。
③对于拍摄不完整的图片,图片中并不包含18位字符,但神经网络输出固定大小的数据,因此,输出结果仍为18位。例如,
拍摄图片为“12345678910”,输出结果为“1x12x134e6e7e19190”即程序会在其中随机补充数据至18位。
个人觉得:网络效果不错,可以识别出身份证号中的绝大多数字符,如果使用更多数据集,更接近实际情况的数据集, 可以取得更好的效果; opencv部分,写的不太还,不能检测出图中所有身份证号,不能完美处理旋转
4 测试视频
最后给大家献上测试视频

5 具体代码
https://github.com/shilei31415/ID_card